Coptic Scriptorium: Digital Research in Coptic Language and Literature
Get started with these popular tools and resources:

Corpora
Read and browse Coptic texts in our corpora, including many with aligned translations.
Browse Corpora
Coptic Dictionary
Lookup a word in an online Coptic Dictionary, developed with our German partners in the KELLIA project.
See Coptic Dictionary
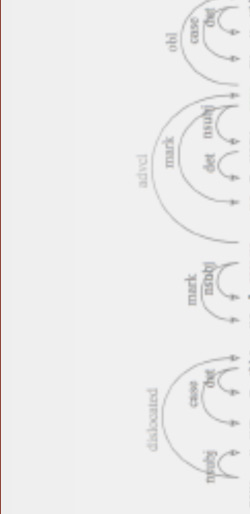
ANNIS Scriptorium
Complete simple searches or complex queries of corpora in our database, ANNIS.
View Tutorial


About
Coptic SCRIPTORIUM is a collaborative, digital project created by Caroline T. Schroeder (University of the Pacific) and Amir Zeldes (Georgetown University).
Full About